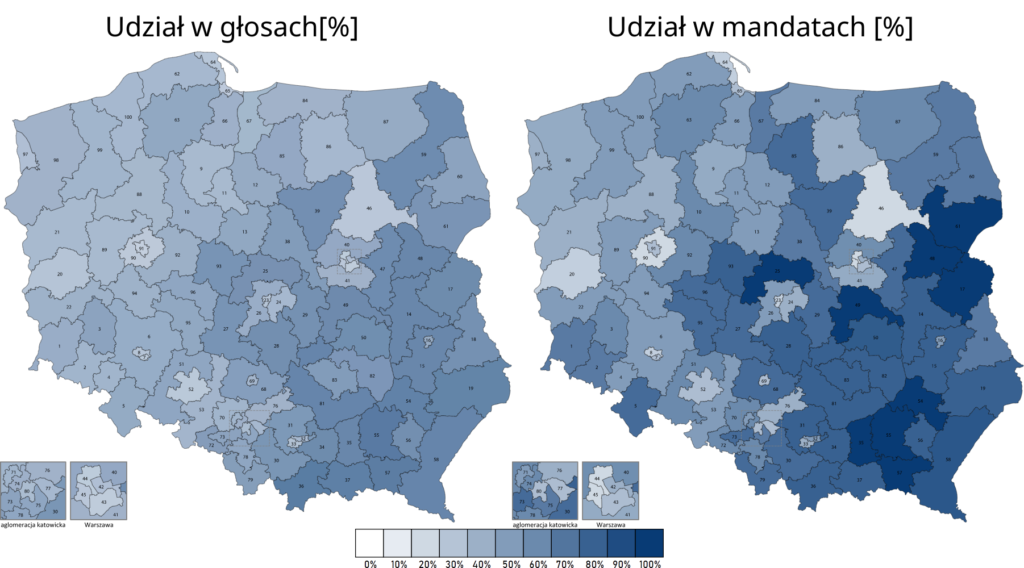
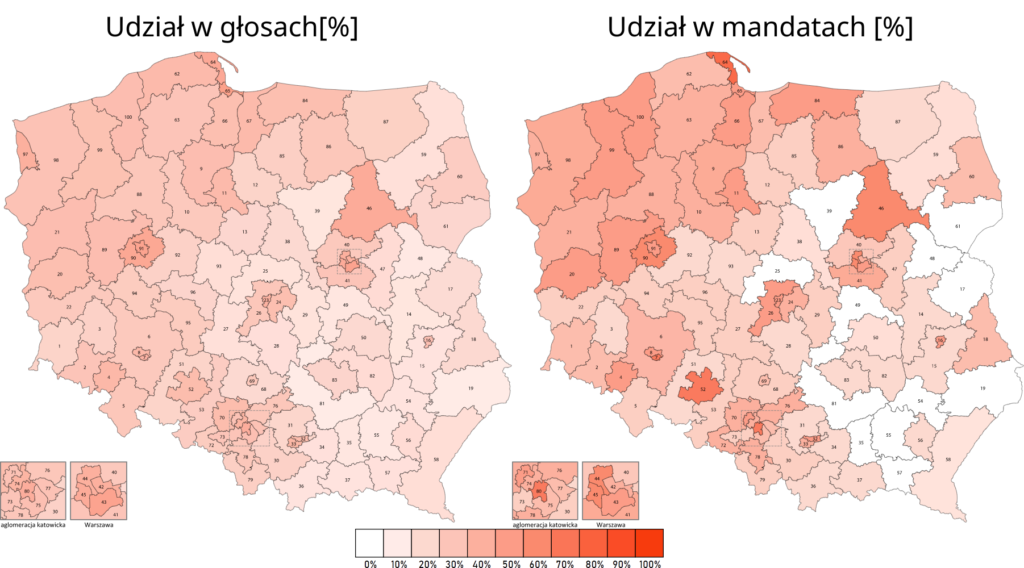
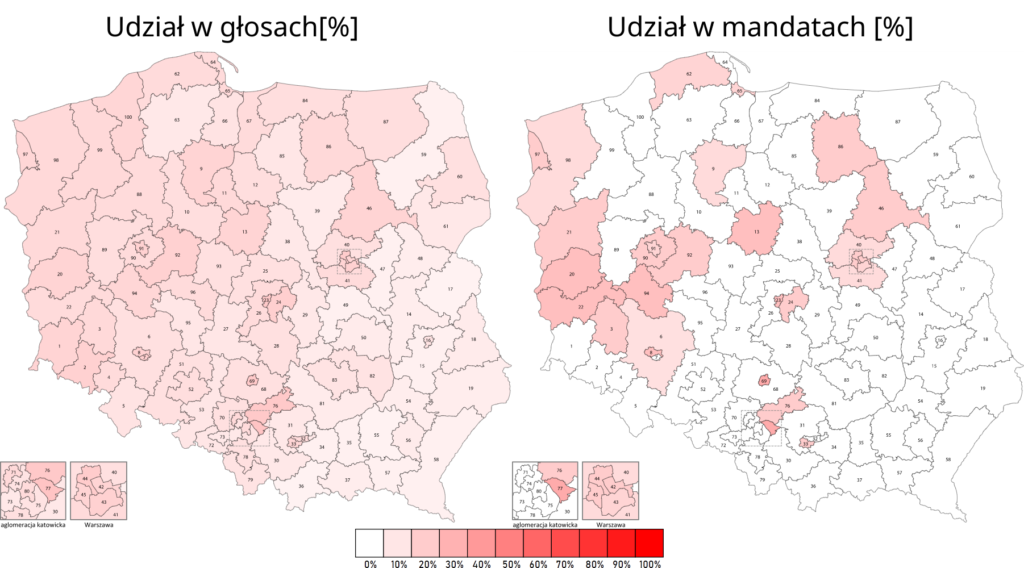
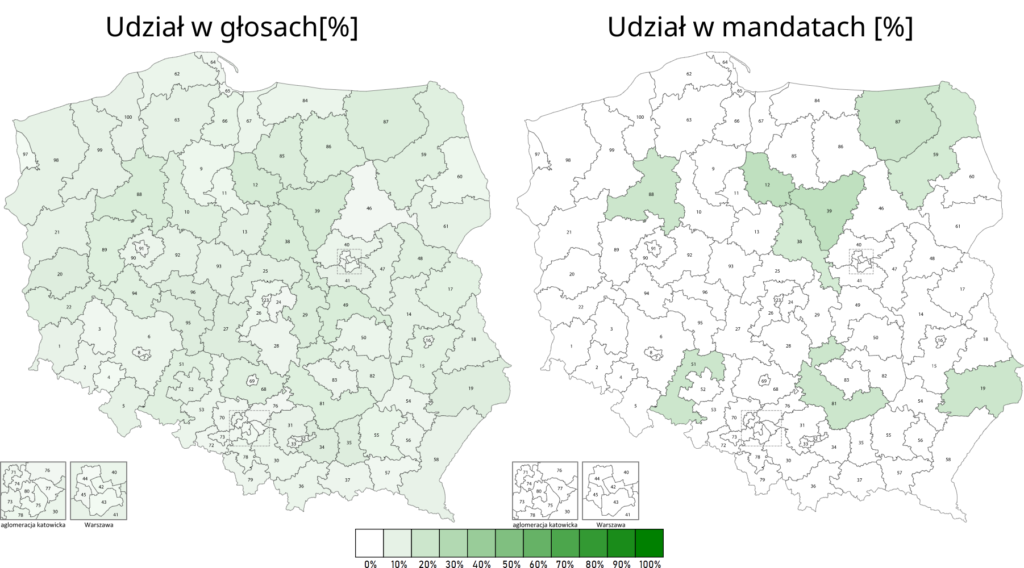
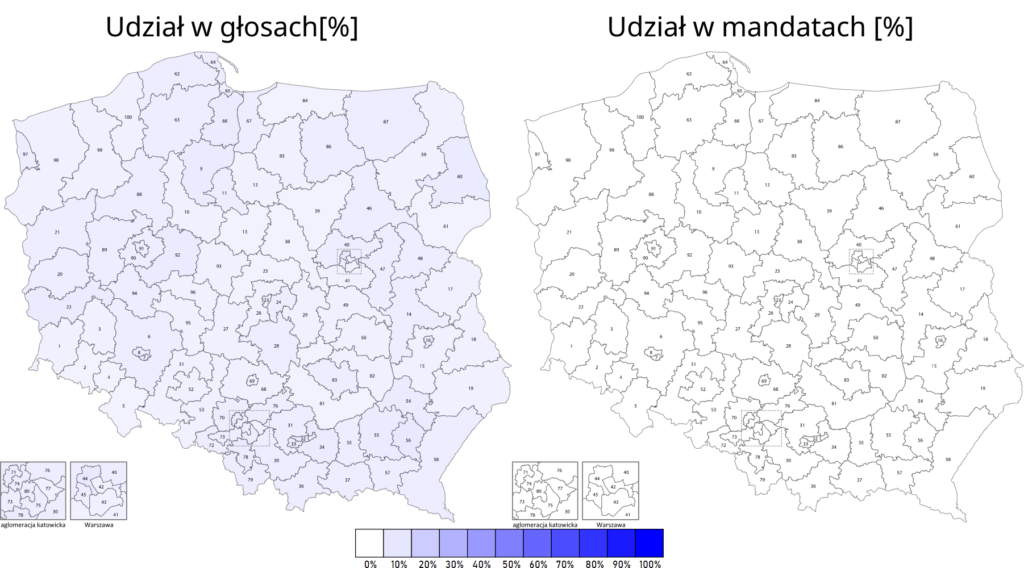
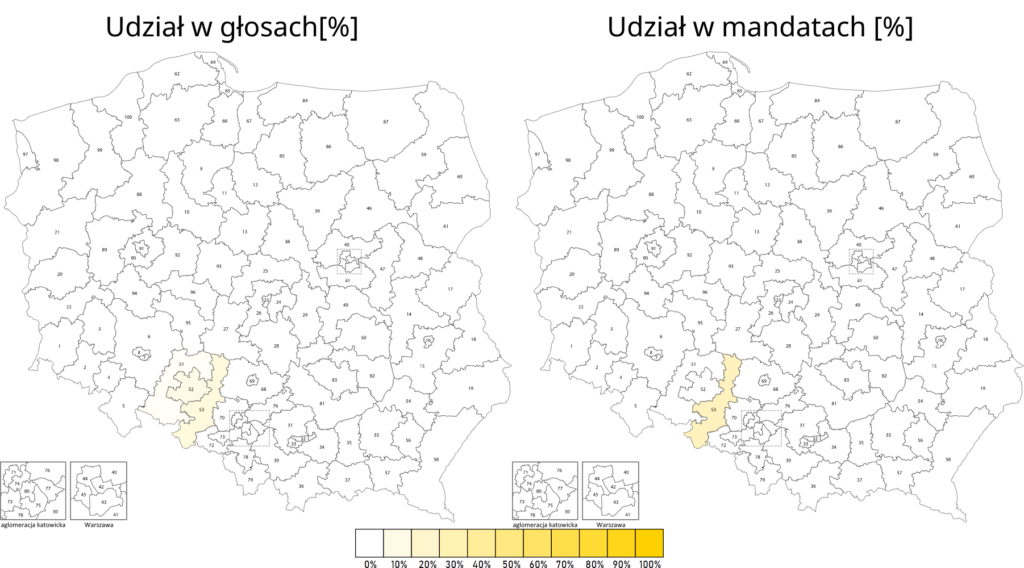
Wracając jeszcze na chwilę do wpisu o konsekwencjach bardziej granularnego podziału na okręgi wyborcze. Zaburzenie proporcjonalności widać jeszcze wyraźniej, gdy porówna się wyniki w poszczególnych okręgach (na wszystkich obrazkach poniżej po lewo) z procentowym udziałem w mandatach w danym okręgu (po prawo).
TLDR: Z pomocą pythonowego pakietu graphviz schematy i grafy można tworzyć jeszcze prościej.
Autor zdjęcia: https://pixabay.com/users/stokpic-692575/
Jak już (mam nadzieję) udało mi się pokazać w części 1, Graphviz jest bardzo ciekawym narzędziem do tworzenia grafów i schematów z postaci czysto tekstowej.
Tworzenie wykresów może być jeszcze prostsze (i zautomatyzowane), gdyż istnieje możliwość zaprzągnięcia do pracy pythona.
Jeżeli mamy już zainstalowany sam program, musimy doinstalować pakiet graphviz w pythonie.
pip install graphviz
Po zainstalowaniu dobrze sprawdzić, czy możemy zaimportować pakiet. W 90% przypadków rozwiązanie ewentualnych problemów można znaleźć w tym wątku na stack overflow.
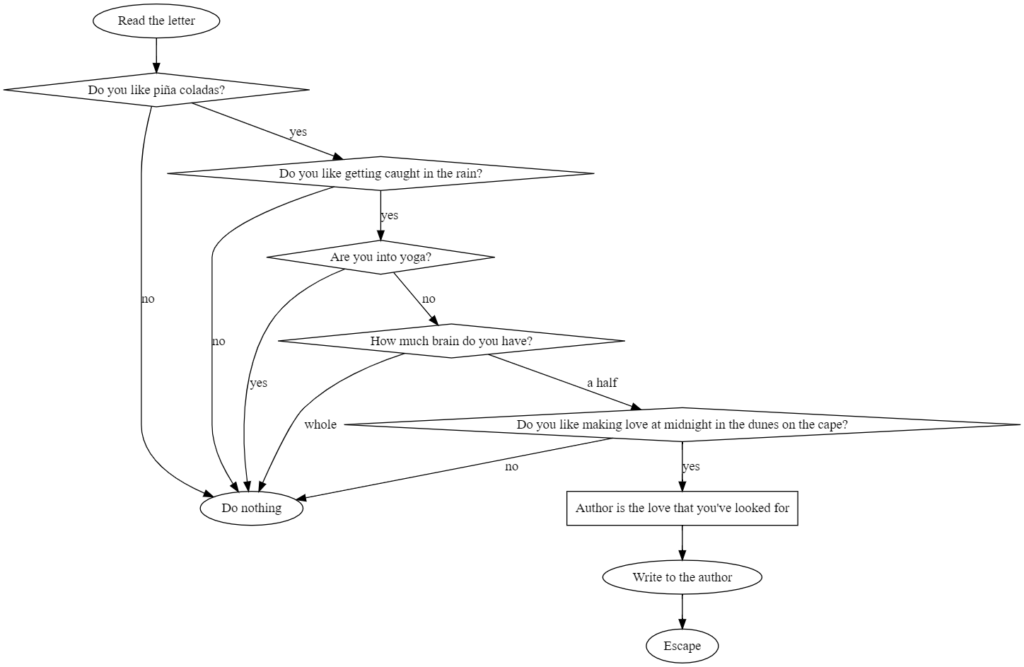
Przykład 1 – Wprowadzanie „Piña colada”
Podobnie jak w „samodzielnej” wersji graphviza, możemy korzystać z dwóch rodzajów schematów `Graph` – grafu nieskierowanego oraz `Digraph` – grafu skierowanego.
from graphviz import Digraph
pina_graph = Digraph(comment='Piña colada')
Powyższe polecenie tworzy pusty graf (z przypisanym komentarzem). Aby dodawać do grafu węzły i krawędzie, wykorzystywane są metody.node() oraz .edge().
pina_graph.node('letter', 'Read the letter')
pina_graph.node('response', 'Write to the author')
pina_graph.node('escape', 'Escape')
pina_graph.node('nothing', 'Do nothing')
Jak widać, w przypadku wierzchołków, podajemy identyfikator node’a (który musi być jednoznaczny) oraz jego opis (który jednoznaczny być już nie musi – dzięki temu możemy mieć na jednym wykresie dwa tak samo podpisane węzły). Możliwe jest także oczywiście dodawanie węzłów z przypisanymi atrybutami:
pina_graph.node('pina', 'Do you like piña coladas?', shape='diamond')
pina_graph.node('rain', 'Do you like getting caught in the rain?', shape='diamond')
pina_graph.node('yoga', 'Are you into yoga?', shape='diamond')
pina_graph.node('brain', 'How much brain do you have?', shape='diamond')
pina_graph.node('sex', 'Do you like making love at midnight in the dunes on the cape?', shape='diamond')
pina_graph.node('author', 'Author is the love that you\'ve looked for', shape='rectangle')
W przypadku krawędzi, podajemy identyfikator początku, końca oraz (jeżeli chcemy) opis:
Na podstawie tak dodanych krawędzi można wygenerować plik dot (tak, aby móc go zapisać, bądź umieścić w README.md naszego repozytorium, z wykorzystaniem gravizo )
print(pina_graph.source)
Co wygeneruje kod w języku dot
// Piña colada
digraph {
letter [label="Read the letter"]
response [label="Write to the author"]
escape [label=Escape]
nothing [label="Do nothing"]
pina [label="Do you like piña coladas?" shape=diamond]
rain [label="Do you like getting caught in the rain?" shape=diamond]
yoga [label="Are you into yoga?" shape=diamond]
brain [label="How much brain do you have?" shape=diamond]
sex [label="Do you like making love at midnight in the dunes on the cape?" shape=diamond]
author [label="Author is the love that you've looked for" shape=rectangle]
pina -> rain [label=yes]
rain -> yoga [label=yes]
yoga -> brain [label=no]
brain -> sex [label="a half"]
sex -> author [label=yes]
pina -> nothing [label=no]
rain -> nothing [label=no]
yoga -> nothing [label=yes]
brain -> nothing [label=whole]
sex -> nothing [label=no]
letter -> pina
author -> response
response -> escape
}
Jeszcze prostsze jest wygenerowanie samego obrazka – wystarczy podać nazwę obiektu.
pina_graph
Przykład 2 – Generowanie automatycznego wykresu
Dzięki temu, że wszystko jest ładnie opakowane w pythonowy interfejs, możliwe jest automatyzowanie tworzenia wykresu i wykorzystanie go do wizualizacji przepływu procesu.
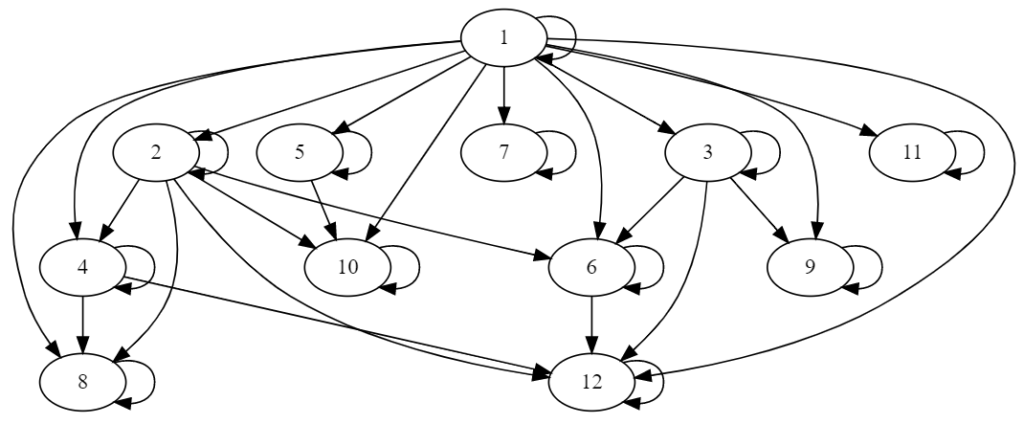
Tutaj mała próbka takiego zastosowania – stworzenie prostego wykresu, pokazującego liczby podzielne przez daną liczbę.
number_graph = Digraph(comment='Dzielniki')
for i in range(1, 13):
number_graph.node(str(i))
for j in range(1, 13):
if j%i == 0:
number_graph.edge(str(i), str(j))
number_graph
Wywołanie tego kodu poskutkuje otrzymaniem takiego obrazka:
Więcej o pakiecie i jego możliwościach można poczytać w jego dokumentacji. Natomiast kod do obu przykładów dostępny jest na githubie
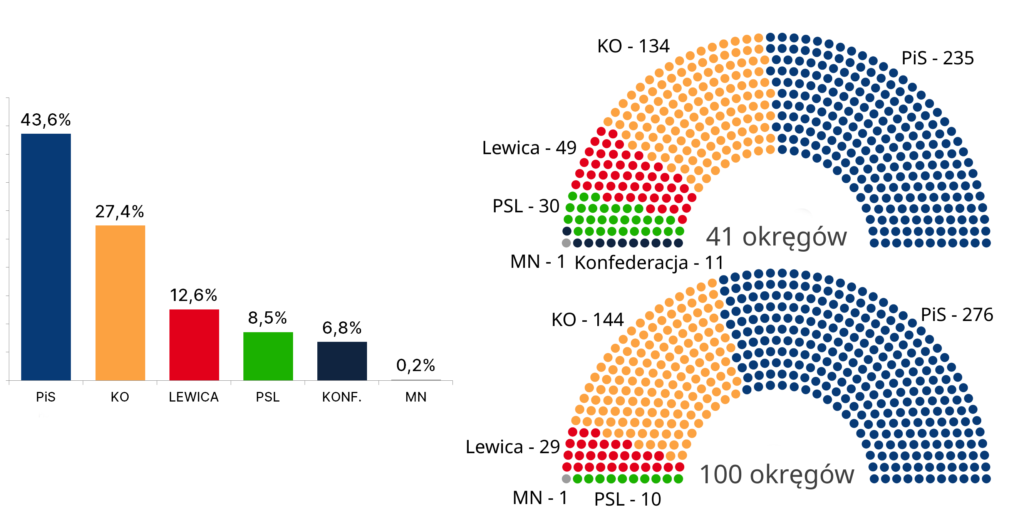
TLDR: Zastosowanie mniejszych okręgów wyborczych wzmocniłoby duże ugrupowania. Przy tej samej liczbie głosów PiS zyskałby 41 posłów.
Niedawno w przestrzeni publicznej (głównie na twitterze) pojawiła się propozycja zastąpienia obecnych okręgów do Sejmu mniejszymi tak, aby „zbliżyć posłów do wyborców”.
Czy wprowadzenie 100 wielomandatowych okręgów wyborczych do Sejmu (w granicach okręgów senackich), powodujące zbliżenie posłów do wyborców (3-8 posłów w w obrębie kilku powiatów), będzie dobrym rozwiązaniem dla Polski? RT
Bez wchodzenia w niepotrzebne spory polityczne postanowiłem sprawdzić, jakie byłyby wyniki takiego eksperymentu. Oparłem się na wynikach do wyborów do sejmu w 2019, dostępnych na stronie PKW: https://sejmsenat2019.pkw.gov.pl/sejmsenat2019/pl/dane_w_arkuszach Przyjęte przeze mnie (dość mocne) założenia:
Okręgi do Sejmu i Senatu miałyby ten sam kształt
Partie nie dokonałyby ruchów koalicyjnych
Wyniki wyborów w poszczególnych komisjach nie zmieniłyby się pomimo zmiany kształtów okręgów wyborczych
Mandaty rozkładałyby się proporcjonalnie do liczby mieszkańców
Do podziału mandatów w okręgach nadal wykorzystywanoby metodę d’Hondta
Rezultaty wyglądałyby następująco:
PiS
KO
Lewica
PSL
Konfederacja
MN
Wyniki przy 100 okręgach
276
144
29
10
0
1
Rzeczywiste wyniki
235
134
49
30
11
1
Różnica
+41
+10
-20
-20
-11
0
Wnioski jakie można wyciągnąć z tej symulacji:
zastosowanie małych okręgów wyborczych premiuje silnie duże ugrupowania – PiS przy dokładnie takiej samej ilości głosów miałby większość 3/5 głosów w Sejmie
najbardziej „karane” są małe partie reprezentowane w miarę równomiernie we wszystkich okręgach (PSL, Konfederacja)
efektywny próg wyborczy może być znacznie wyższy niż 5% – Konfederacja pomimo uzyskania 6,81% głosów nie wprowadziłaby do sejmu żadnego posła
rozwiązanie to prawdopodobnie doprowadziłoby do konieczności utworzenia bloku partii opozycyjnych i do efektywnego wytworzenia się systemu dwupartyjnego
Tworzenie schematów bywa trudnym zajęciem. By zostało dobrze zrobione, wymaga od autora umiejętności graficznych. Dodanie nowych elementów bardzo często wiąże się z koniecznością zmiany układu całego schematu. Dodatkowo, wersjonowanie takiego pliku bywa utrudnione – zwłaszcza jeżeli jest on zapisany w formacie graficznym trudno wychwycić różnicę pomiędzy kolejnymi iteracjami pliku.
Graphviz pozwala wyeliminować obie te słabości i wygenerować estetyczne diagramy, na podstawie „kodu źródłowego”, w języku dot. Aby wypróbować jego możliwości, można go oczywiście zainstalować, ale można też wykorzystać jedno z dostępnych API, np to na witrynie GitHuba.
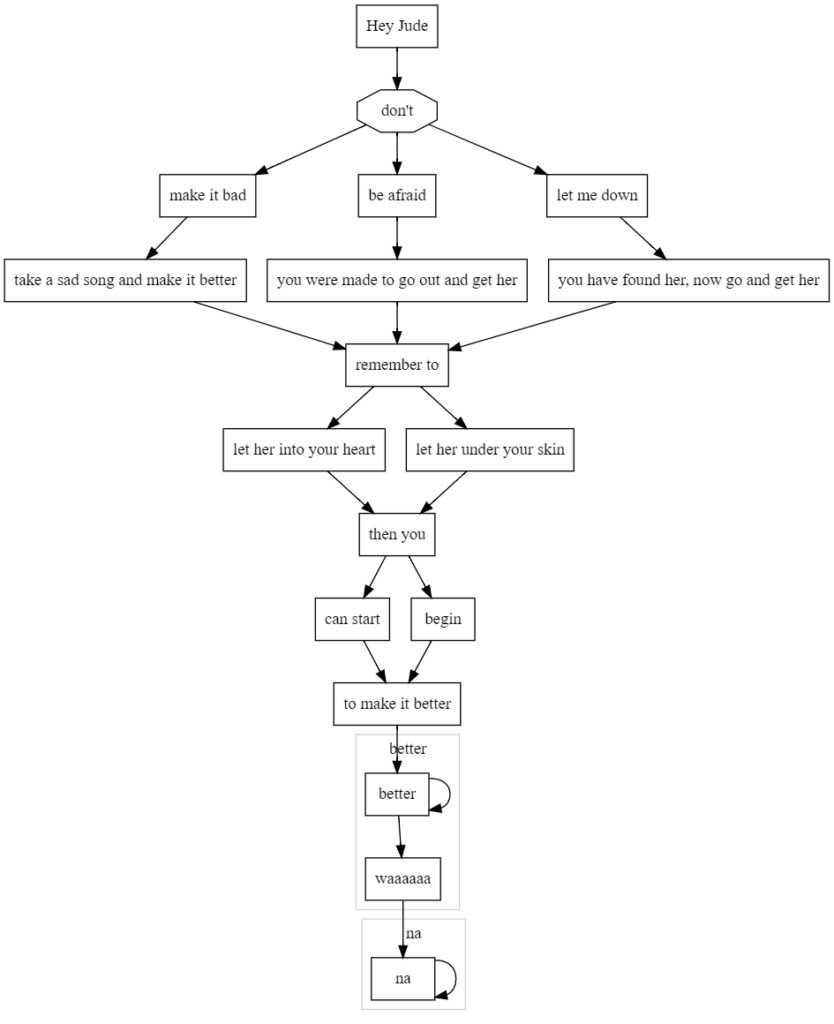
Załóżmy, że chcemy stworzyć wykres, obrazujący przebieg zwrotek piosenki Hey Jude Beatelsów:
Kod źródłowy dla takiego wykresu będzie wyglądał następująco:
digraph G {
node [shape = box];
/*1 zwrotka*/
start -> negation -> worsening -> song_improvement ->
remembering -> permission -> indication ->
start_permission -> improvement;
improvement -> better;
waaaaaa -> na;
/*2 zwrotka*/
negation -> fear -> conquering -> remembering ->
injection -> indication -> origin -> improvement;
/*3 zwrotka*/
negation -> disappointment -> retrieval -> remembering;
start [label = "Hey Jude"];
negation [label = "don't" shape = octagon];
worsening [label = "make it bad"]
song_improvement [label = "take a sad song and make it better"]
remembering [label = "remember to"]
permission [label = "let her into your heart"]
indication [label = "then you"]
start_permission[label ="can start"]
improvement[label = "to make it better"]
fear[label = "be afraid"]
conquering[label = "you were made to go out and get her"]
injection[label = "let her under your skin"]
origin[label = "begin"]
disappointment[label = "let me down"]
retrieval[label = "you have found her, now go and get her"]
subgraph cluster_na {
color=lightgrey;
na -> na;
label = "na";
}
subgraph cluster_better {
color=lightgrey;
better -> better -> waaaaaa;
label = "better";
}
}
Dostępne są dwa rodzaje grafów – skierowane digraph oraz nieskierowane graph.
Jak można zaobserwować, diagram składa się z 3 głównych elementów: – węzłów (node) – krawędzi (egde) – podgrafów (subgraph) Każdemu z nich mogą zostać przypisane atrybuty. Do najważniejszych z nich należy atrybut label – odpowiada on za to, jak będzie podpisany dany węzeł bądź krawędź. Można również ustawić tam kolor, (color), kształt (shape) bądź wypełnienie. Ich pełna lista jest dostępna tutaj.
Polączenia pomiędzy węzłami tworzy się poprzez zastosowanie łącznika ->, jeżeli chce się pokazać kierunek, bądź — jeżeli chce się pokazać jedynie połączenie.
Komentarze można dodawać w takim samym stylu jak w C/C++ – jednolinijkowe porzez //, wielolinijkowe przez /* */.
Czasami podczas pracy z pandasowym DataFrame’m zachodzi potrzeba wykonania bardziej nietrywialnej operacji na zbiorze. Załóżmy, że analizujemy ceny nieruchomości w Kalifornii, korzystając z popularnego zbioru California Housing Prices.
import pandas as pd
import numpy as np
california_housing = pd.read_csv("./sample_data/california_housing_train.csv")
Nasz przełożony podpowiada nam, że cena domów, w których sypialnie zajmują dużą część budynku powinny być tańsze niż wskazuje na to mediana wartości budynku. W związku z tym, chcemy zmniejszyć cenę dla takich budynków, natomiast zwiększyć dla budynków, w których taka sytuacja nie występuje.
Oczywiste wydaje się być użycie apply(). Tak napisany kod zajmuje Google Colabowi 594 ms. Nie wydaje się być to tragedią. Dataset ma jednak jedynie 17 000 rekordów. Załóżmy, że nasz dataset jest jednak 100 razy większy:
Wówczas wykonanie tej samej operacji zajmuje już Colabowi ponad minutę. Zakładając, że mamy takich operacji do wykonania kilka (albo, nie daj Boże, musimy to robić regularnie) jest to zauważalna strata czasu.
Z pomocą przychodzi nam np.vectorize(). Dzięki jego zastosowaniu, możemy zachować przejrzysty kod, który będzie liczył się o wiele szybciej – kod zapewniający tą samą funkcjonalność, dla zbioru o 1 700 000 rekordów liczy się 481 ms – ponad 130 razy szybciej niż analogiczny kod z wykorzystaniem apply()
Korzystanie z niej wygląda nieco inaczej niż w przypadku apply(). Najlepiej najpierw zdefiniować funkcję operującą na pojedynczym rzędzie (bądź kolumnie).
Vectorize tworzy z niej funkcję operującą już na „kolumnach” – jako argumenty do utworzonej funkcji (druga para nawiasów) podajemy „kolumny”.