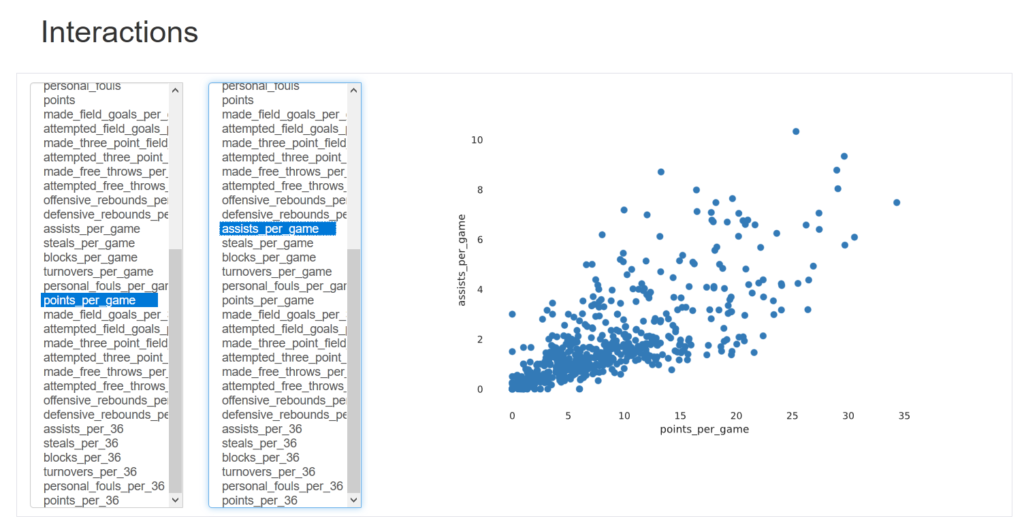
TLDR: pakiet Click pozwala na przygotowanie w łatwy sposób aplikacji konsolowej, zarządzając m.in. parametrami

Czasami gdy przygotowaliśmy jakiś przydatny (bądź nie) kawałek kodu, chcielibyśmy go udostępnić światu. Dobrze wówczas zadbać o wygodny interfejs do jego wykorzystywania. Jeżeli ma być to aplikacja konsolowa można w tym celu wykorzystać pakiet click
pip install clickZałóżmy, że korzystając z pakietu basketball_reference_web_scraper chcemy „wydrukować” personalia zawodnika zdobywającego najwięcej punktów w NBA – przygotowaliśmy sobie skrypt dla bieżącego sezonu.
from basketball_reference_web_scraper import client
players = pd.DataFrame(client.players_season_totals(season_end_year=2020))
players['team'] = players['team'].astype(str).str[5:].str.replace("_", " ")
players['positions'] = players['positions'].astype(str).str.extract("'([^']*)'")
max_player = players.iloc[players['points'].idxmax()]
print("name:", max_player['name'], "-", "points", "in", "2020", "season:", max_player['points'])Automatyzacja tego zadania dla wielu sezonów do postaci wykonywalnego skryptu jest bajecznie prosta:
import click
from basketball_reference_web_scraper import client
import pandas as pd
@click.command()
@click.argument('season_end_year', type=int)
def max_player(season_end_year):
"""Print name and number of points in of player with most points in NBA season which ends in SEASON_END_YEAR
SEASON_END_YEAR is a int number
"""
players = pd.DataFrame(client.players_season_totals(season_end_year=season_end_year))
players['team'] = players['team'].astype(str).str[5:].str.replace("_", " ")
players['positions'] = players['positions'].astype(str).str.extract("'([^']*)'")
max_player = players.iloc[players['points'].idxmax()]
print("name:", max_player['name'])
print("points", "in", season_end_year-1, "/", season_end_year, "season:", max_player['points'])
if __name__ == '__main__':
max_player()@click.command() to dekorator który zamienia funkcję poniżej w obiekt command – nie zagłębiając się w szczegóły, to konieczne aby następne polecenia zadziałały.
@click.argument() definiuje argument skryptu – wartość wpisywaną po nazwie skryptu.
Wywołanie skryptu jest już bardzo proste:
python max_player.py 2010Co zwraca nam informację o ówczesnym królu strzelców:
name: Kevin Durant
points in 2009 / 2010 season: 2472Proste jest także dodawanie „parametrów” skryptu – załóżmy, że chcemy dodać możliwość sprawdzania innych statystyk niż punkty. Służy do tego dekorator @click.option()
import click
from basketball_reference_web_scraper import client
import pandas as pd
@click.command()
@click.option('--stat', '-s', type=click.STRING, help="Stat used to determine max player", default="points")
@click.argument('season_end_year', type=int)
def max_player(season_end_year, stat):
"""Print name and number of points (assists, rebounds) of player with most points (assists, rebounds) in NBA season which ends in SEASON_END_YEAR
SEASON_END_YEAR is an int number
"""
if stat not in ("points", "assists", "rebounds", "steals", "blocks"):
print("stat not recognized")
players = pd.DataFrame(client.players_season_totals(season_end_year=season_end_year))
players['team'] = players['team'].astype(str).str[5:].str.replace("_", " ")
players['positions'] = players['positions'].astype(str).str.extract("'([^']*)'")
max_player = players.iloc[players[stat].idxmax()]
print("name:", max_player['name'])
print(stat, "in", season_end_year-1, "/", season_end_year, "season:", max_player['points'])
if __name__ == '__main__':
max_player()Dzięki zastosowaniu tego możemy sprawdzić np. kto był królem asyst w 2015…
python max_player.py --stat=assists 2015i przypomnieć sobie „złotą erę” Chrisa Paula:
name: Chris Paul
assists in 2014 / 2015 season: 1564Swoistą wisienką na torcie jest automatyczne generowanie helpa – wywołanie:
python max_player.py --helpzwróci nam ładnie sformatowany manual
Usage: max_player.py [OPTIONS] SEASON_END_YEAR
Print name and number of points (assists,
rebounds) in of player with most points in NBA
season which ends in SEASON_END_YEAR
SEASON_END_YEAR is a int number
Options:
-s, --stat TEXT Stat used to determine max
player
--help Show this message and exit.Zastosowań clicka jest oczywiście dużo, dużo więcej – choćby wprowadzanie haseł ale o tym już najlepiej poczytać na stronie dokumentacji