
TLDR: Kiedy miara staje się „celem”, przestaje być dobrą miarą.

Zjawisko to można było zaobserwować historycznie (co poruszyłem w napisanej jakiś czas temu pierwszej części). Prawo to bierze nazwę od Charlesa Goodharta – brytyjskiego ekonomisty.
W oryginale brzmiało ono: „Każda obserwowana statystycznie zależność ma skłonność do zawodzenia, w momencie w którym zaczyna być wykorzystywana do celów regulacyjnych” i dotyczyła prowadzenia brytyjskiej polityki monetarnej. Goodhart zauważył, że próba wprowadzenia ograniczeń na banki komercyjne przez bank centralny nie przyniesie zamierzonego efektu, ponieważ znajdą one sposób na świadczenie danej usługi pod inną nazwą oraz w inny sposób. Aby zoptymalizować swoje zyski „skalibrują się” do wybranego kryterium.
Podobne zjawisko można zauważyć w przypadku stron internetowych. Problemem przed którym stanęli producenci wyszukiwarek było stworzenie algorytmu pozycjonowania – w Google początkowo był to PageRank (o którego dokładniejszych założeniach i implementacji można przeczytać bardzo ciekawy artykuł na Geeks for Geeks). W miarę rozwoju tych algorytmów bardzo szybko pojawiły się firmy zajmujące się pozycjonowaniem stron w internecie. Za opłatą wykorzystywały one logikę działania tych metod (które premiowały m.in. występowanie słów kluczowych oraz hiperłączy prowadzących do strony) po to, aby premiować strony w wynikach wyszukiwania. Powoduje to sytuację, w której najwyżej nie są „najlepsze” wyniki, a jedynie te „najlepiej spozycjonowane”. Z problemem nie udało się do tej pory skutecznie wygrać – przykład może stanowić próba sprawdzenia czy najbliższa niedziela jest handlowa, czy nie:

Bardzo często efekt ten można zaobserwować także w korporacjach. W momencie gdy premie są przyznawane za spełnienie danego kryterium, mogą wydarzyć się niekorzystne z punktu widzenia całej firmy, ale optymalne dla danego działu sytuacje. Dla przykładu – dział odpowiedzialny za windykację jest rozliczany jedynie za liczbę dłużników, których przekonali do spłaty. Może to doprowadzić do sytuacji, w której nie będą przypominać klientom o dacie spłaty, przez co wygenerują sobie dużo „łatwych” punktów premiowych – klientów, którzy zamierzali zapłacić, a jedynie o tym zapomnieli. Dla firmy koszt wzrośnie (dział windykacji będzie miał więcej przypadków, więc nie będzie miał czasu na częstsze napastowanie rzeczywistych dłużników), pomimo tego, że kryterium będzie wyglądać coraz lepiej.
W świecie finansowym pewnym problemem jest także kwestia „uczenia się” przez klientów tego co może być składnikiem skoringu kredytowego. W związku z tym klienci mogą podejmować próby oszukiwania na wniosku (np. zatajania rozdzielności majątkowej albo liczby dzieci na utrzymaniu), bądź nawet podejmować akcje, które mają w ich mniemaniu podnieść ich wiarygodność w oczach banku – np. brać małe niepotrzebne pożyczki, by „stworzyć dobrą historię kredytową” albo dostawać dodatkowe przelewy od znajomych, tak aby wytworzyć iluzję wyższego osiąganego dochodu. Działanie to powoduje, że dane kryterium przestaje być tak dobre, jak powinno według danych historycznych.
W przypadku bezzałogowych statków powietrznych, ważnym kryterium które dla wielu osób czy instytucji decyduje o zakupie danego produktu jest jego zasięg sterowania – to jak faktycznie daleko „dron” może odlecieć. W związku z tym niektórzy producenci stosują bardzo kierunkowe anteny – które zapewniają duży zasięg w jednym kierunku, ale „nie radzą sobie” zupełnie w innym. W skrajnych przypadkach może to powodować, że kopter będzie miał tendencję do zrywania połączenia po nawet lekkim obróceniu się. Innym przykładem z tej działki jest manipulowanie długotrwałością – czasem pozostawania w powietrzu. Można stworzyć konstrukcję, która przy bezwietrznej pogodzie, bez payloadu (akcesorium faktycznie wykonującego zadanie – np. kamery) będzie pozostawać w powietrzu bardzo długo (co zostanie skrupulatnie zaznaczone na pudełku). Ze względu na zbyt mały zapas mocy czas skróci się jednak dramatycznie, jeśli zamocujemy tam kamerę i faktycznie będziemy chcieli coś nakręcić.

W uczeniu maszynowym prawo to także potrafi zmaterializować się, czasami w nieoczywisty sposób. Pierwszy, najbardziej rzucający się w oczy, to kwestia przeuczania modelu. Jeżeli nasz model jest zbyt skomplikowany w stosunku do liczby posiadanych danych, może się zdarzyć, zastosowanie kryterium jakości klasyfikacji na zbiorze treningowym może skutkować jego przeuczeniem. Model „zapamięta” wtedy kombinacje – zamiast uogólnić rozwiązanie.
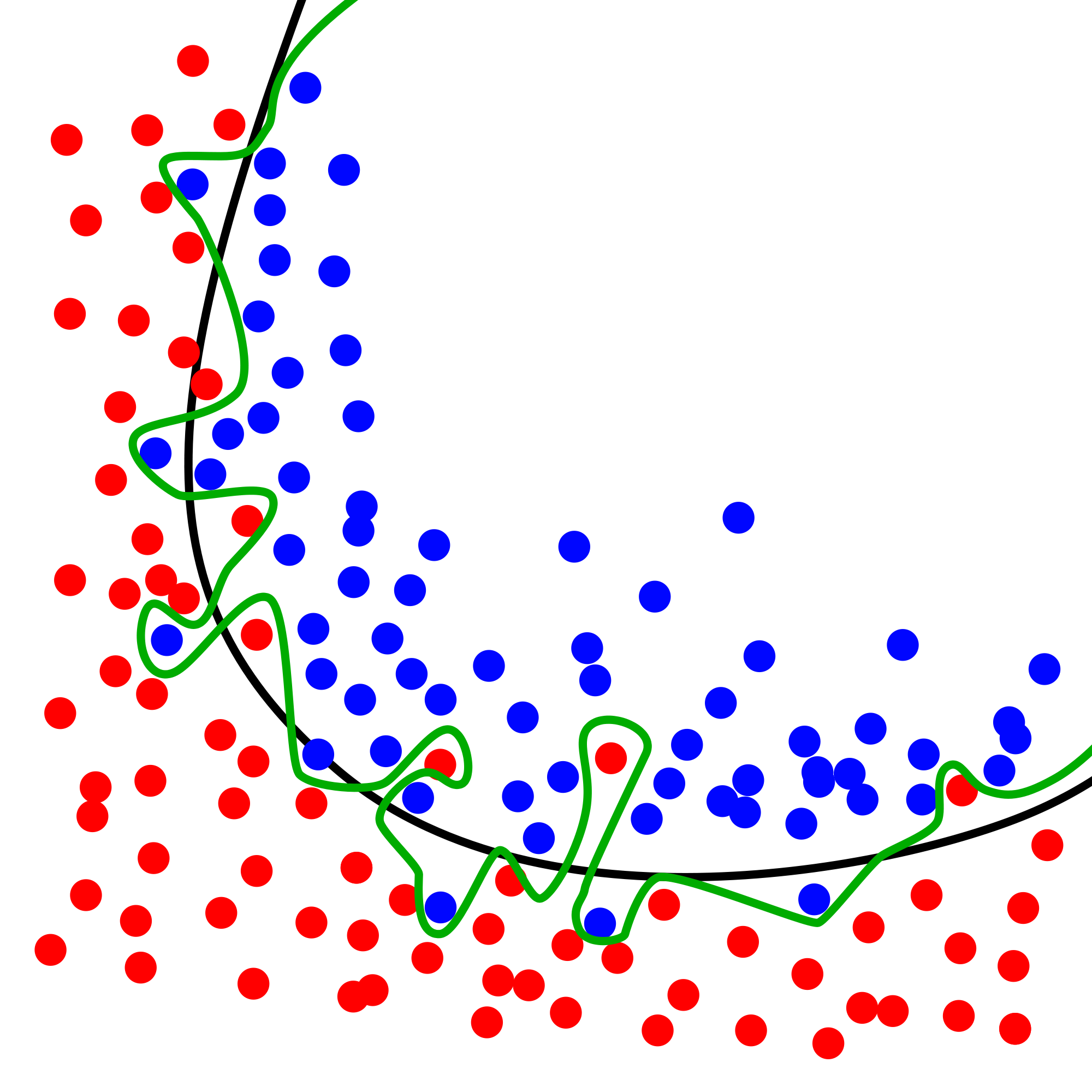
Innym, bardziej subtelnym i trudniejszym do wychwycenia problemem jest sama kwestia definicji sukcesu i doboru próbki treningowej. Załóżmy, że pracujemy w firmie telekomunikacyjnej i chcemy stworzyć model, który będzie odrzucał klientów z wysokim prawdopodobieństwem powstania zadłużenia. Jeżeli wybierzemy jako definicję „zły klient to taki, który w ciągu roku od podpisania umowy przynajmniej raz spóźnił się z fakturą”, to model nauczony na takiej definicji może znakomicie wyglądać na papierze. Zbiór prawdopodobnie będzie lepiej zbilansowany, co może przełożyć się na jego wyniki w kryteriach jakości. Jednak ze względu na to że znakomita większość opóźnień w fakturach to krótkie opóźnienia, to model może nauczyć się cech charakteryzujących ludzi, mających skłonność do takich zachowań (np. młody wiek, korzystanie z telefonu do wykonywania opłat), a nie cech charakteryzujących „zatwardziałych dłużników”. W związku z tym możemy pozbyć się z populacji części osób, które generują zysk, a nie tych, którzy powodują straty.
Innym przykładem może być zagadnienie dość szeroko opisywane w branżowych portalach – model który miał rozróżniać wilki od psów rasy husky, pomimo tego, że dawał sobie świetnie radę na zbiorach treningowych i testowych nie działał zupełnie w rzeczywistym środowisku. Po długiej analizie wag modelu, rozwiązanie tej zagadki okazało się zaskakująco proste. Wszystkie zdjęcia wilków były wykonane w czasie jednej sesji w czasie zimy, podczas gdy zdjęcia psów pochodziły z internetu i były wykonywane w różnych porach roku i różnych miejscach. Model nauczył się zatem (z dużą dokładnością) wykrywać śnieg. (więcej na ten temat tutaj)

Reasumując – pomimo tego, że „uczenie maszynowe” brzmi bardzo górnolotnie, a metody za nim stojące są czasami wyjątkowo wysublimowane, to nadal jest to jedynie algorytm minimalizujący jakieś kryterium, bez głębszego rozumienia problemu.