TLDR: pandas-profiling to bardzo wygodne narzędzie do przeprowadzenia szybkiej analizy eksploracyjnej – obszerny raport można uzyskać za pomocą 2 linijek

Bardzo często spotykamy się po raz pierwszy z nieznanym datasetem. Chcąc podejrzeć co się w nim znajduje mamy kilka opcji. Najbardziej oczywistą wydaje się (po wczytaniu do pandasa) wykonanie na nim metody head() lub tail(). Ale to daje nam tylko pobieżną informację o kilku pierwszych (bądź ostatnich) rekordach.
Jeżeli chcemy głębiej zajrzeć w dane, z pomocą może nam przyjść pakiet pandas-profiling, który całą czarną robotę wykona za nas.
Ponieważ wielkimi krokami zbliżają się play-offy w lidze NBA możemy spróbować poczuć się jak autor profilu „O Futbolu Statystycznie” i spróbować pogrzebać w statystykach najlepszej ligi koszykarskiej. Morze statystyk można znaleźć na wspaniałej stronie basketball referrence. Tak się składa, że pewien autor stworzył swoiste pythonowe api do tej strony – pakiet basketball_reference_web_scraper .
!pip install --upgrade --quiet pandas_profiling
!pip install --quiet basketball_reference_web_scraper
import numpy as np
import pandas as pd
from pandas_profiling import ProfileReport
from basketball_reference_web_scraper import clientPo zainstalowaniu i zaimportowaniu niezbędnych pakietów można brać się do faktycznej analizy – za swój cel obierzemy graczy, którzy grali w bieżącym sezonie (2019/20). Zbiór wymaga małego oczyszczenia w polach dotyczących pozycji oraz klubu.
players = pd.DataFrame(client.players_season_totals(season_end_year=2020))
players['team'] = players['team'].astype(str).str[5:].str.replace("_", " ")
players['positions'] = players['positions'].astype(str).str.extract("'([^']*)'")Aby móc lepiej porównywać dokonania zawodników dodamy statystyki uśrednione liczbą meczów oraz uśrednione do 36 minut.
columns = ['made_field_goals', 'attempted_field_goals', 'made_three_point_field_goals',
'attempted_three_point_field_goals', 'made_free_throws',
'attempted_free_throws', 'offensive_rebounds', 'defensive_rebounds',
'assists', 'steals', 'blocks', 'turnovers', 'personal_fouls', 'points']
for stat in columns:
players[stat+"_per_game"] = players[stat] / players["games_played"]
for stat in columns:
players[stat+"_per_36"] = players[stat] / players["minutes_played"] * 36.Z tak przygotowanym datasetem możemy rozpocząć naszą analizę. Utworzenie raportu jest banalnie proste – wystraczy utworzyć obiekt zawierający „podsumowanie”:
profile = ProfileReport(players, title='NBA Players Profiling Report')A następnie wyświetlić bądź zapisać:
profile.to_widgets() # wyświetlenie w postaci osadzonego "widżetu"
profile.to_notebook_iframe() # wyświetlenie w postaci osadzonego kodu html
profile.to_file("nba_players.html") # zapis do pliku htmlRaport składa się z kilku części. W pierwszej z nich znajdują się najbardziej podstawowe informacje o datasecie – liczba (i rodzaj) kolumn, liczba rekordów, informacja o rekordach pustych i zduplikowanych:
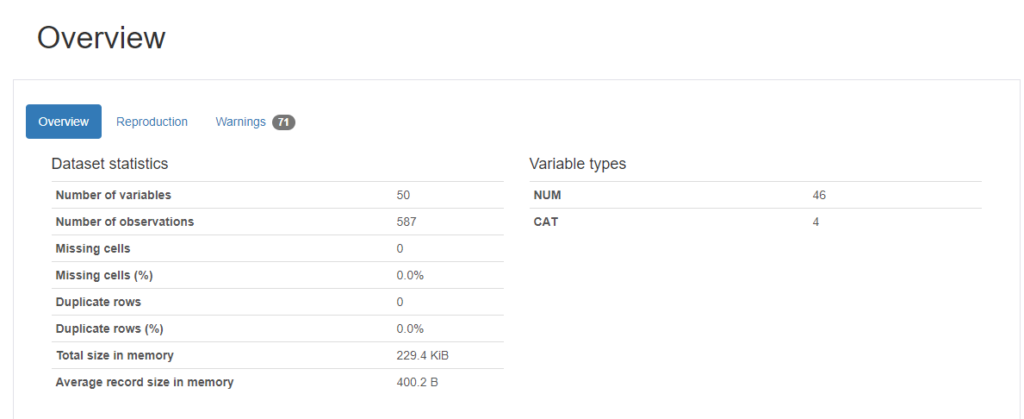
Kolejną część stanowią statystyki dotyczące poszczególnych kolumn datasetu – w przypadku zmiennych kategorycznych, dotyczą one m.in. liczby i liczności poszczególnych kategorii oraz liczby braków danych
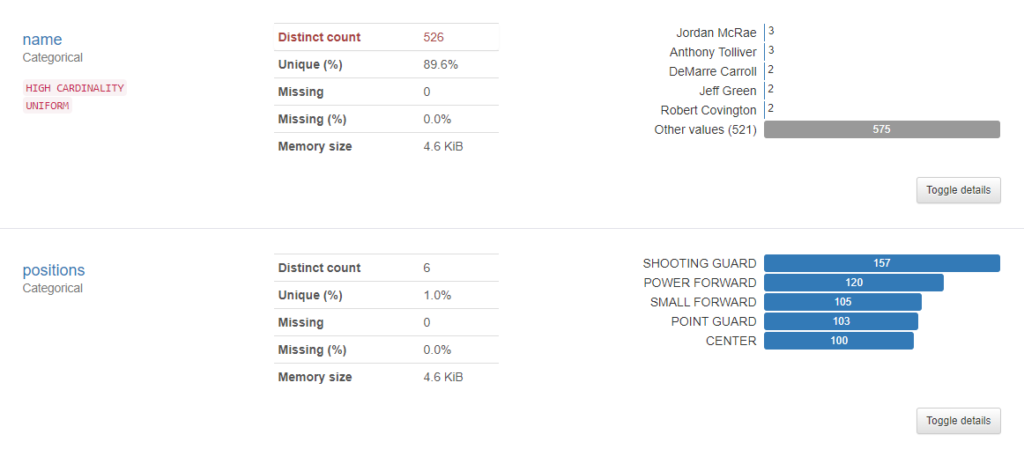
W przypadku zmiennych liczbowych informacji jest jeszcze więcej – m.in. rozkład zmiennej, liczba zer, minimalne i maksymalne wartości

Dodatkowe informacje można znaleźć odsłaniając ukrytą zawartość (przycisk toggle details).
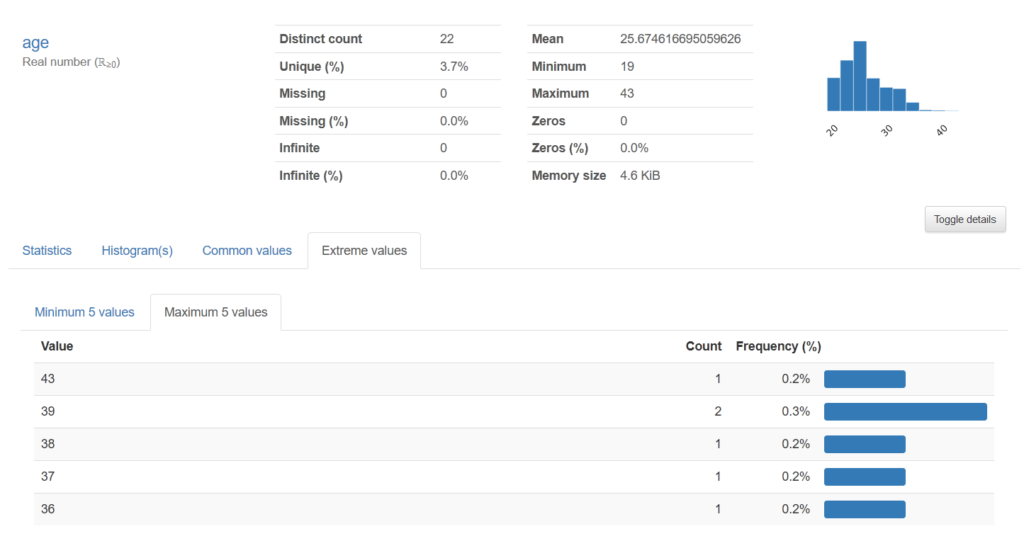
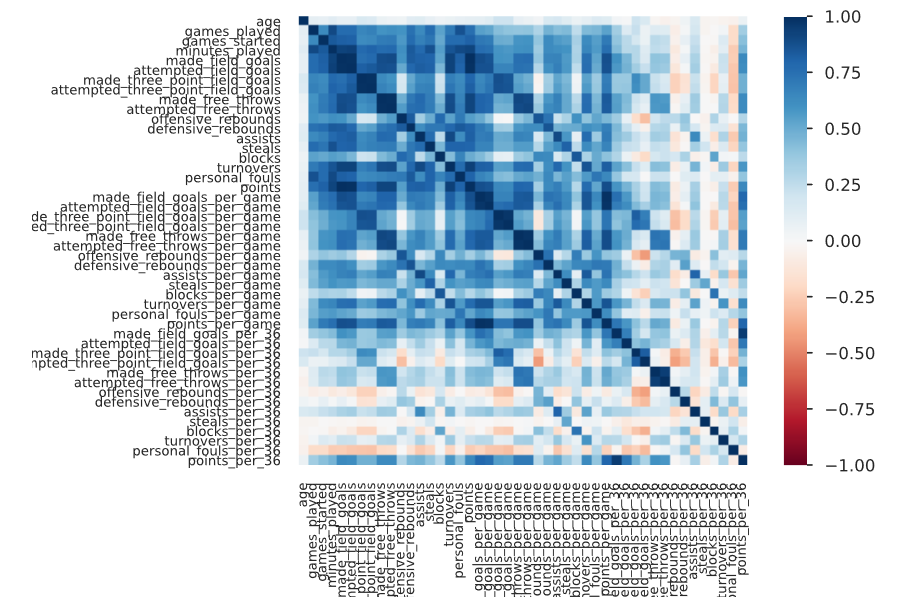
Ponadto generowana jest macierz korelacji pomiędzy zmiennnymi
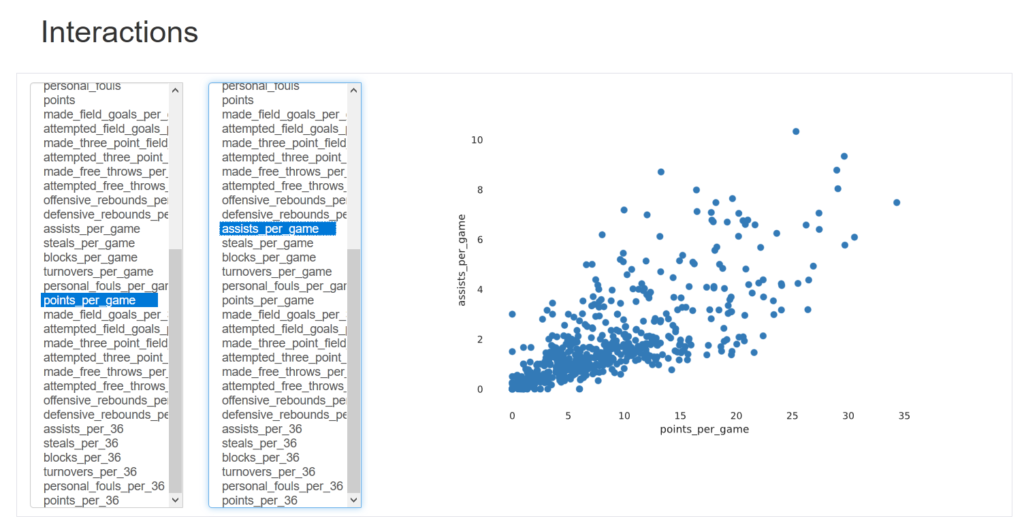
Jednak zdecydowanie najlepszym efektem jest interaktywny wykres pozwalający na sprawdzenie interakcji pomiędzy dowolnymi dwoma zmiennymi. Dla przykładu to jak wyglądają średnie punktów i asyst w meczu
Niestety – to rozwiązanie ma jednak swoje minusy – wygenerowany plik (przy dużej liczbie zmiennych) może dużo ważyć – dla tego datasetu (50 kolumn) plik z analizą w postaci html-a waży ponad 150 MB
Kod można (jak zawsze) podejrzeć na gitlabie